rselenium tutorial
RSelenium allows us to integrate from within R testing and manipulation of projects such as shiny, sauceLabs.Installation
install.packages("RSelenium")
Or development version from GitHub
install.packages("devtools")
devtools::install_github("ropensci/RSelenium")
library("RSelenium")
Usage
Connecting to a Selenium Server
What is a Selenium Server?
Selenium Server is a standalone java program which allows you to run HTML test suites in a range of different browsers, plus extra options like reporting.
You may, or may not, need to run a Selenium Server, depending on how you intend to use Selenium-WebDriver (RSelenium).
Do I need to run a Selenium Server?
If you intend to drive a browser on the same machine that RSelenium is running on then you will need to have Selenium Server running on that machine.
How do I get the Selenium Server stand-alone binary?
RSelenium has a built-in function that will download the stand-alone java binary and place it in the RSelenium package location in the /bin/ directory.
If you would like to install elsewhere the function takes a dir argument and can also update an existing binary.
Note: checkForServer is now defunct.
Users in future can find the function in
file.path(find.package("RSelenium"), "examples/serverUtils").
The recommended way to run a selenium server is via Docker.
Alternatively see the RSelenium::rsDriver function.
If you would like to download the binary manually it is currently found here.
Look for selenium-server-standalone-x.xx.x.jar.
How do I run the Selenium Server?
There is a utility function included in RSelenium to run an existing stand-alone Selenium Server binary.
RSelenium::startServer()
By default it looks in the RSelenium package /bin/ directory.
It has an optional dir argument if your binary is elsewhere.
Alternatively you can run the binary manually.
Open a console in your OS and navigate to where the binary is located and run:
java -jar selenium-server-standalone-x.xx.x.jar
By default the Selenium Server listens for connections on port 4444.
How do I connect to a running server?
RSelenium has a main reference class named remoteDriver.
To connect to a server you need to instantiate a new remoteDriver with appropriate options.
# RSelenium::startServer() if required
require(RSelenium)
remDr <- remoteDriver(remoteServerAddr = "localhost"
, port = 4444
, browserName = "firefox"
)
It would have been sufficient to call remDr <- remoteDriver() but the options where explicitly listed to show how one may connect to an arbitrary ip/port/browser etc.
More detail maybe found on the sauceLabs vignette.
To connect to the server use the open method.
remDr$open()
RSelenium should now have a connection to the Selenium Server.
You can query the status of the remote Server using the status method.
> remDr$getStatus()
$os
arch name version
"amd64" "Linux" "3.8.0-35-generic"
$java
version
"1.6.0_27"
$build
revision time version
"ff23eac" "2013-12-16 16:11:15" "2.39.0"
Navigating using RSelenium
Basic Navigation
To start with we navigate to a url.
remDr$navigate("http://www.google.com")
Then we navigate to a second page.
remDr$navigate("http://www.bbc.co.uk")
> remDr$getCurrentUrl()
[[1]]
[1] "http://www.bbc.co.uk/"
We can go backwards and forwards using the methods goBack and goForward.
remDr$goBack()
> remDr$getCurrentUrl()
[[1]]
[1] "https://www.google.com/"
remDr$goForward()
> remDr$getCurrentUrl()
[[1]]
[1] "http://www.bbc.co.uk/"
To refresh the current page you can use the `refresh method.
remDr$refresh()
Accessing elements in the DOM
The DOM stands for the Document Object Model.
It is a cross-platform and language-independent convention for representing and interacting with objects in HTML, XHTML and XML documents.
Interacting with the DOM will be very important for us with Selenium and the webDriver provides a number of methods in which to do this.
A basic html page is
<!DOCTYPE html>
<html>
<body>
<h1>My First Heading</h1>
<p>My first paragraph.</p>
</body>
</html>
The query box on the front page of http://www.google.com has html code input id="gbqfq" class="gbqfif" associated with it.
The full html associated with the input tag is:
<input type="text" value="" autocomplete="off" name="q" class="gbqfif" id="gbqfq" style="border: medium none; padding: 0px; margin: 0px; height: auto; width: 100%; background: url("data:image/gif;base64,R0lGODlhAQABAID/AMDAwAAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw%3D%3D") repeat scroll 0% 0% transparent; position: absolute; z-index: 6; left: 0px; outline: medium none;" dir="ltr" spellcheck="false">
Search by id.
To find this element in the DOM a number of methods can be used.
We can search by the id.
remDr$navigate("http://www.google.com/ncr")
webElem <- remDr$findElement(using = 'id', value = "gbqfq")
> webElem$getElementAttribute("id")
[[1]]
[1] "gbqfq"
> webElem$getElementAttribute("class")
[[1]]
[1] "gbqfif"
Search by class.
We can also search by class name.
webElem <- remDr$findElement(using = 'class name', "gbqfif")
> webElem$getElementAttribute("class")
[[1]]
[1] "gbqfif"
> webElem$getElementAttribute("type")
[[1]]
[1] "text"
Search using css-selectors
The class is denoted by . when using css selectors.
To search on class using css selectors we would use
webElem <- remDr$findElement(using = 'css selector', "input.gbqfif")
and to search on id using css-selectors
webElem <- remDr$findElement(using = 'css selector', "input#gbqfq")
A good example of searching using css-selectors is given here.
Search by name
To search using the name if given of the element.
Note that ids are unique in a given html page.
Names are not necessarily unique.
webElem <- remDr$findElement(using = 'name', "q")
> webElem$getElementAttribute("name")
[[1]]
[1] "q"
> webElem$getElementAttribute("id")
[[1]]
[1] "gbqfq"
Search using xpath
The final option is to search using xpath.
Normally one would use xpath by default when searching.
Xpath using id.
webElem <- remDr$findElement(using = 'xpath', "//*/input[@id = 'gbqfq']")
Xpath using class.
webElem <- remDr$findElement(using = 'xpath', "//*/input[@class = 'gbqfif']")
Sending events to elements
To illustrate how to interact with elements we will again use the http://www.google.com/ncr as an example.
Sending text to elements
Suppose we would like to search for R cran on google.
We would need to find the element for the query box and send the appropriate text to it.
We can do this using the sendKeysToElement method for the webElement class.
remDr$navigate("http://www.google.com/ncr")
webElem <- remDr$findElement(using = "xpath", "//*/input[@id = 'gbqfq']")
webElem$sendKeysToElement(list("R Cran"))
Sending key presses to elements
We should see that the text R Cran has now been entered into the query box.
How do we press enter.
We can simply send the enter key to query box.
The enter key would be denoted as "\uE007".
So we could use:
remDr$navigate("http://www.google.com/ncr")
webElem <- remDr$findElement(using = "xpath", "//*/input[@id = 'gbqfq']")
webElem$sendKeysToElement(list("R Cran", "\uE007"))
It is not very easy to remember utf8 codes for appropriate keys so a mapping has been provided in RSelenium.
`?selkeys’ will bring up a help page explaining the mapping.
The utf codes given here have been mapped to easy to remember names.
To use selkeys we would send the following
remDr$navigate("http://www.google.com/ncr")
webElem <- remDr$findElement(using = "xpath", "//*/input[@id = 'gbqfq']")
webElem$sendKeysToElement(list("R Cran", key = "enter"))
Typing selKeys into the console will bring up the list of mappings.
Sending mouse events to elements
For this example we will go back to the google frontpage and search forR Cran then we will click the link for the The Comprehensive R Archive Network.
remDr$navigate("http://www.google.com/ncr")
webElem <- remDr$findElement(using = "xpath", "//*/input[@id = 'gbqfq']")
webElem$sendKeysToElement(list("R Cran", key = "enter"))
<li class="g"> contains the search results we can find all the search entries on the first page using the findElements method.
The header for each link is contained further in with a <h3 class = "r"> tag.
We will access the h3 headers first.
It will be succinct to find these elements using css selectors.
webElems <- remDr$findElements(using = 'css selector', "li.g h3.r")
resHeaders <- unlist(lapply(webElems, function(x){x$getElementText()}))
> resHeaders
[1] "The Comprehensive R Archive Network"
[2] "Comprehensive R Archive"
[3] "Mirrors"
[4] "Contributed Packages"
[5] "R for Mac OS X"
[6] "Download R 3.0.2"
[7] "CRAN Repository Policy"
[8] "The R Project for Statistical Computing"
[9] "Cran - Wikipedia, the free encyclopedia"
[10] "Comprehensive R Archive Network (CRAN) - StatLib - Carnegie"
[11] "CRAN - Package R.methodsS3"
[12] "CRAN - Package R.cache"
[13] "Ubuntu - Details of package r-cran-sp in lucid"
We can see that the first link is the one we want but in case googles search results change we refer to it as
webElem <- webElems[[which(resHeaders == "The Comprehensive R Archive Network")]]
How do we click the link.
We can use the clickElement method:
webElem$clickElement()
> remDr$getCurrentUrl()
[[1]]
[1] "http://cran.r-project.org/"
> remDr$getTitle()
[[1]]
[1] "The Comprehensive R Archive Network"
Injecting JavaScript
Sometimes it is necessary to interact with the current url using JavaScript.
This maybe necessary to call bespoke methods or to have more control over the page for example by adding the JQuery library to the page if it is missing. Selenium has two methods we can use to execute JavaScript namelyexecuteScript and executeAsyncScript from the remoteDriver class.
We return to the google front page to investigate these methods.
Injecting JavaScript synchronously
Returning to the google homepage we can find the element for the google image.
The image has id = "hplogo" and
we can use this in an xpath or search by id etc to select the element.
In this case we use css selectors:
remDr$navigate("http://www.google.com/ncr")
webElem <- remDr$findElement("css selector", "img#hplogo")
Is the image visible? Clearly it is but we can check using javascript.
> remDr$executeScript("return document.getElementById('hplogo').hidden;", args = list())
[[1]]
[1] FALSE
Great so the image is not hidden indicated by the FALSE.
We can hide it executing some simple JavaScript.
remDr$executeScript("document.getElementById('hplogo').hidden = true;", args = list())
> remDr$executeScript("return document.getElementById('hplogo').hidden;", args = list())
[[1]]
[1] TRUE
So now the image is hidden.
We used an element here given by id = "hplogo".
We had to use the JavaScript functiongetElementById to access it.
It would be nicer if we could have used webElem which we had specified earlier.
If we pass a webElement object as an argument to either executeScript or executeAsyncScript RSelenium will pass it in an appropriate fashion.
> remDr$executeScript(script = "return arguments[0].hidden = false;", args = list(webElem))
[[1]]
[1] FALSE
Notive how we passed the web element to the method executeScript.
The script argument defines the script to execute in the form of a function body.
The value returned by that function will be returned to the client.
The function will be invoked with the provided args.
If the function returns an element then this will be returned as an object of class webElement:
test <- remDr$executeScript("return document.getElementById('gbqfq');", args = list())
> test[[1]]
[1] "remoteDriver fields"
$remoteServerAddr
[1] "localhost"
$port
[1] 4444
$browserName
[1] "firefox"
$version
[1] ""
$platform
[1] "ANY"
$javascript
[1] TRUE
$autoClose
[1] FALSE
$nativeEvents
[1] TRUE
$extraCapabilities
list()
[1] "webElement fields"
$elementId
[1] 1
> class(test[[1]])
[1] "webElement"
attr(,"package")
[1] "RSelenium"
Injecting JavaScript asynchronously
I will briefly touch on asynch versus sync calls here.
With the current firefox and selenium server combination (firefox 26.0 sel server 2.39.0) I had issues with async javascript calls when nativeEvents = TRUE (the default) was used.
For the example below I switched to nativeEvents = FALSE
remDr <- remoteDriver(nativeEvents = FALSE)
remDr$open()
remDr$navigate("http://www.google.com/ncr")
remDr$setAsyncScriptTimeout(10000)
Observe:
remDr$executeAsyncScript("setTimeout(function(){ alert('Hello'); arguments[arguments.length -1]('DONE');},5000); ", args = list())
versus
remDr$executeScript("setTimeout(function(){ alert('Hello');},5000); return 'DONE';", args = list())
The async version waits until the callback (defined as the last argument) is called.
Frames and Windows
In the context of a web browser, a frame is a part of a web page or browser window which displays content independent of its container, with the ability to load content independently.
Frames in Selenium
We will demonstrate interacting with frames by way of example.
The R project conviently contains frames so we shall use RSelenium to interact with it.
Assume we have a remoteDriver opened.
remDr$navigate("http://www.r-project.org/")
> htmlParse(remDr$getPageSource()[[1]])
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>The R Project for Statistical Computing</title>
<link type="image/x-icon" href="favicon.ico" rel="icon">
<link type="image/x-icon" href="favicon.ico" rel="shortcut icon">
<link href="R.css" type="text/css" rel="stylesheet">
</head>
<frameset border="0" cols="1*, 4*">
<frameset rows="120, 1*">
<frame frameborder="0" name="logo" src="logo.html">
<frame frameborder="0" name="contents" src="navbar.html">
</frameset>
<frame frameborder="0" name="banner" src="main.shtml">
<noframes>
<h1>The R Project for Statistical Computing</h1>
Your browser seems not to support frames,
here is the <A href="navbar.html">contents page</A> of the R Project's
website.
</noframes>
</frameset>
</html>
We can see the content is contained in three frames and we dont appear to have access to the content within a frame.
Put in the browser we see all the content:
remDr$maxWindowSize()
remDr$screenshot(display = TRUE)
RProject front page
 To access the content we have to switch to a frame using the
To access the content we have to switch to a frame using the switchToFrame method of the remoteDriver class.
webElems <- remDr$findElements(using = "tag name", "frame")
# webElems <- remDr$findElements("//frame") # using xpath
> sapply(webElems, function(x){x$getElementAttribute("src")})
[[1]]
[1] "http://www.r-project.org/logo.html"
[[2]]
[1] "http://www.r-project.org/navbar.html"
[[3]]
[1] "http://www.r-project.org/main.shtml"
remDr$switchToFrame(webElems[[2]])
> htmlParse(remDr$getPageSource()[[1]])
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>R Contents</title>
<link href="R.css" type="text/css" rel="stylesheet">
</head>
<body>
<em class="navigation">About R</em><br><a target="banner" href="about.html">What is R?</a><br><a target="banner" href="contributors.html">Contributors</a><br><a target="banner" href="screenshots/screenshots.html">Screenshots</a><br><a target="banner" href="news.html">What's new?</a><br><p>
<em class="navigation">Download, Packages</em><br><a target="banner" href="http://cran.r-project.org/mirrors.html">CRAN</a>
</p>
<p>
<em class="navigation">R Project</em><br><a target="banner" href="foundation/main.html">Foundation</a><br><a target="banner" href="foundation/memberlist.html">Members & Donors</a><br><a target="banner" href="mail.html">Mailing Lists</a><br><a target="_top" href="http://bugs.R-project.org">Bug Tracking</a><br><a target="_top" href="http://developer.R-project.org">Developer Page</a><br><a target="banner" href="conferences.html">Conferences</a><br><a target="banner" href="search.html">Search</a><br></p>
<p>
<em class="navigation">Documentation</em><br><a target="banner" href="http://cran.r-project.org/manuals.html">Manuals</a><br><a target="banner" href="http://cran.r-project.org/faqs.html">FAQs</a><br><a target="_top" href="http://journal.r-project.org">The R Journal</a><br><!--
<a href="doc/Rnews/index.html" target="banner">Newsletter</a><br>
--><a target="_top" href="http://wiki.r-project.org">Wiki</a><br><a target="banner" href="doc/bib/R-books.html">Books</a><br><a target="banner" href="certification.html">Certification</a><br><a target="banner" href="other-docs.html">Other</a><br></p>
<p>
<em class="navigation">Misc</em><br><a target="_top" href="http://www.bioconductor.org">Bioconductor</a><br><a target="banner" href="other-projects.html">Related Projects</a><br><a target="_top" href="http://rwiki.sciviews.org/doku.php?id=rugs:r_user_groups">User Groups</a><br><a target="banner" href="links.html">Links</a><br></p>
</body>
</html>
Now we see the source code of the navigation sidePanel.
Notice how we used a webElement in the method switchToFrame.
To further demonstrate we are now “in” this frame lets get all the href attributes:
webElems <- remDr$findElements("css selector", "[href]")
sapply(webElems, function(x){x$getElementAttributes("href")})
> unlist(sapply(webElems, function(x){x$getElementAttribute("href")}))
[1] "http://www.r-project.org/R.css"
[2] "http://www.r-project.org/about.html"
[3] "http://www.r-project.org/contributors.html"
[4] "http://www.r-project.org/screenshots/screenshots.html"
[5] "http://www.r-project.org/news.html"
[6] "http://cran.r-project.org/mirrors.html"
[7] "http://www.r-project.org/foundation/main.html"
[8] "http://www.r-project.org/foundation/memberlist.html"
[9] "http://www.r-project.org/mail.html"
[10] "http://bugs.r-project.org/"
[11] "http://developer.r-project.org/"
[12] "http://www.r-project.org/conferences.html"
[13] "http://www.r-project.org/search.html"
[14] "http://cran.r-project.org/manuals.html"
[15] "http://cran.r-project.org/faqs.html"
[16] "http://journal.r-project.org/"
[17] "http://wiki.r-project.org/"
[18] "http://www.r-project.org/doc/bib/R-books.html"
[19] "http://www.r-project.org/certification.html"
[20] "http://www.r-project.org/other-docs.html"
[21] "http://www.bioconductor.org/"
[22] "http://www.r-project.org/other-projects.html"
[23] "http://rwiki.sciviews.org/doku.php?id=rugs:r_user_groups"
[24] "http://www.r-project.org/links.html"
Notice if we pass a NULL value to the method switchToFrame we move back to the default view.
remDr$switchToFrame(NULL)
> htmlParse(remDr$getPageSource()[[1]])
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>The R Project for Statistical Computing</title>
<link type="image/x-icon" href="favicon.ico" rel="icon">
<link type="image/x-icon" href="favicon.ico" rel="shortcut icon">
<link href="R.css" type="text/css" rel="stylesheet">
</head>
<frameset border="0" cols="1*, 4*">
<frameset rows="120, 1*">
<frame frameborder="0" name="logo" src="logo.html">
<frame frameborder="0" name="contents" src="navbar.html">
</frameset>
<frame frameborder="0" name="banner" src="main.shtml">
<noframes>
<h1>The R Project for Statistical Computing</h1>
Your browser seems not to support frames,
here is the <A href="navbar.html">contents page</A> of the R Project's
website.
</noframes>
</frameset>
</html>
Finally we can switch to the main panel using a name
remDr$switchToFrame("banner")
> htmlParse(remDr$getPageSource()[[1]])
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>The R Project for Statistical Computing</title>
<link href="R.css" type="text/css" rel="stylesheet">
</head>
<body>
<h1 align="left">The R Project for Statistical Computing</h1>
<p>
</p>
<center>
<a href="misc/acpclust.R"><img border="0" alt="R Graphics Demo" src="hpgraphic.png"></a>
</center>
<p>
</p>
<table width="100%" border="1"><tbody>
<tr><td>
<h2>Getting Started:</h2>
<ul>
<li>R is a free software environment for statistical
computing and graphics.
It compiles and runs on a wide variety
of UNIX platforms, Windows and MacOS.
To <strong><a href="http://cran.r-project.org/mirrors.html">download R</a></strong>, please
choose your preferred <a href="http://cran.r-project.org/mirrors.html">CRAN mirror</a>.
</li>
<li>
If you have questions about R like how to download and install
the software, or what the license terms are,
please read our <a href="http://cran.R-project.org/faqs.html">answers to frequently asked questions</a> before you send an email.
</li>
<p>
</p>
</ul>
</td></tr>
<tr><td>
<h2>News:</h2>
<ul>
<li>
<strong>R version 3.0.2</strong> (Frisbee Sailing) has been
released on 2013-09-25.</li>
<li>
<strong><a href="http://www.r-project.org/useR-2013" target="_top">
useR! 2013</a></strong>,
took place at the University of Castilla-La Mancha,
Albacete, Spain, July 10-12 2013.
</li>
<li>
<a target="_top" href="http://journal.r-project.org/current.html">
<strong>The R Journal Vol.5/1</strong></a>
is available.
</li>
<li>
<strong>R version 2.15.3</strong> (Security Blanket) has been
released on 2013-03-01.</li>
<!-- Dead stuff, for later reuse:
<li>
<strong><a href="http://cran.R-project.org/src/base-prerelease">
R 3.0.2 (Frisbee Sailing) prerelease versions</a></strong> will
appear starting
September 15.
Final release is scheduled for September 25, 2013.<br>
Thanks to Erin Hodgess for the idea leading to the name.
</li>
<li>
<strong><a href="http://cran.R-project.org/src/base-prerelease">
R 3.0.1 prerelease versions</a></strong> will appear starting
May 6.
Final release is scheduled for May 16, 2013.<br>
</li>
<li>
The R Foundation as been awarded <a
href="soc11/index.html">
fifteen slots for R projects</a> in the <a
href="http://code.google.com/soc/" target="_top">Google Summer of Code 2011</a>.
<li>
<strong><a target="_top"
href="http://www.r-project.org/dsc-2009"> DSC 2009</a></strong>,
The 6th workshop on Directions in Statistical Computing, has been
held at the Center for Health and Society, University of
Copenhagen, Denmark, July 13-14, 2009.
</li>
<li>
<strong><a target="_top" href="http://www.agrocampus-rennes.fr/math/useR-2009/">
useR! 2009</a></strong>, the R user conference,
has been be held at Agrocampus Rennes, France, July 8-10, 2009.
<li>
The R Foundation as been awarded <a
href="soc09/index.html">
four slots for R projects</a> in the <a
href="http://socghop.appspot.com/org/home/google/gsoc2009/rf" target="_top">Google Summer of Code 2009</a>.
<li>We have started to collect ideas for the <a
href="http://www.r-project.org/soc09">Google Summer of Code 2009</a>.
</li>
-->
</ul>
<p>
</p>
</td></tr>
</tbody></table>
<p>
This server is hosted by the <a target="_top" href="http://statmath.wu.ac.at">Institute for Statistics and Mathematics</a> of <a target="_top" href="http://www.wu.ac.at">WU (Wirtschaftsuniversien)</a>.
</p>
</body>
</html>
Windows in Selenium
The easiest way to illustrate Windows in RSelenium is again by way of example.
We will use the R project website.
First we select the download R element in the main frame.
remDr$navigate("http://www.r-project.org")
remDr$switchToFrame("banner")
webElem <- remDr$findElement("partial link text", "download R")
> webElem$getElementText()
[[1]]
[1] "download R"
We now send a selection of key presses to this element to open the link it points to in a new window.
If you did it manually you would move the mouse to the element right click on the link press the down arrow key twice then press enter.
We will do the same
loc <- webElem$getElementLocation()
> loc[c('x','y')]
$x
[1] 347
$y
[1] 519
remDr$mouseMoveToLocation(webElement = webElem) # move mouse to the element we selected
remDr$click(2) # 2 indicates click the right mouse button
remDr$sendKeysToActiveElement(list(key = 'down_arrow', key = 'down_arrow', key = 'enter'))
Notice now that a new windows has opened on the remote browser.
> remDr$getCurrentWindowHandle()
[[1]]
[1] "{573d17e5-b95a-41b9-a65f-04092b6a804b}"
> remDr$getWindowHandles()
[[1]]
[1] "{573d17e5-b95a-41b9-a65f-04092b6a804b}" "{3336c9b3-4c46-4a95-853e-2786a529ba29}"
> remDr$getTitle()
[[1]]
[1] "The R Project for Statistical Computing"
>
> remDr$switchToWindow("{3336c9b3-4c46-4a95-853e-2786a529ba29}")
> remDr$getTitle()
[[1]]
[1] "CRAN - Mirrors"
So using the code above one can observe how to switch between different windows on the remote browser.
Take 1: traditional http request
When possible, it makes sense to use the simple traditional methods.
So I first tried to extract these tickers with the popular httr R package
by making standard http requests.
>library('httr')
url <- 'https://www.fidelity.com/fund-screener/evaluator.shtml#!&ft=BAL_all&ntf=N&expand=%24FundType&rsk=5'
page <- GET(>url)
Success…
>print(http_status(page))
## $category
## [1] "success"
##
## $message
## [1] "success: (200) OK"
But did our http request return the information we want?
page_text <- content(page, as='text')
Nope – can’t find the tickers (one of them anyway).
>grepl('GMMAX', page_text, ignore.case=>T)
## [1] FALSE
Nope – can’t even find the fund name that I see in the table from the webpage in my browser.
>grepl('Aberdeen', page_text, ignore.case=>T)
## [1] FALSE
It appears that the content of interest is being generated dynamically with Javascript and Ajax on this webpage.
So the raw HTML of this page doesn’t help us much.
My plan B was to grab the url for each fund from the table, navigate to that fund’s page, and extract the ticker from there.
However these links weren’t in our http response.
I noticed that the URLs for each fund followed a simple consistent structure.
https://fundresearch.fidelity.com/mutual-funds/summary/72201F433 for example.
I thought maybe I could find 72201F433 which looks like some sort of fund ID in a list with all fund IDs in the http response.
No dice.
Plan C – Selenium.
Take 2: Selenium
I used the RSelenium R package for this mini project.
There are also Selenium bindings for Python, Java, C#, Javascript and Ruby
which make replicating this process in your programming language of choice relatively straightforward.
Step 1: Fire up Selenium
sample:
require(RSelenium)
checkForServer()
startServer()
remDr<-remoteDriver()
remDr$open()
remDr$getStatus()
remDr$navigate("http://fyed.elections.on.ca/fyed/en/form_page_en.jsp")
p.codes<-c('m1p4v4', 'n3t2y3', 'n2h3v1')
webElem<-remDr$findElement(using = 'id', value = "pcode")
webElem$sendKeysToElement(list(p.codes[1])) # send the first post code to the element
remDr$findElement("id", "en_btn_arrow")$clickElement() # find the submit button and click it collect info using RSelenium
>library('RSelenium')
checkForServer() ># search for and download Selenium Server java binary.
Only need to run once.
startServer() ># run Selenium Server binary
remDr <- remoteDriver(browserName="firefox", port=4444) ># instantiate remote driver to connect to Selenium Server
remDr$>open(silent=>T) ># open web browser
Step 2: Start scraping
To figure which DOM elements I wanted Selenium extract, I used the Chrome Developer Tools which can be invoked by right clicking a fund in the table and selecting Inspect Element.
The HTML displayed here contains exactly what we want, what we didn’t see with our http request.
Since I want to grab all the funds at once, I tell Selenium to select the whole table.
Going a few levels up from the individual cell in the table I’ve selected, I see that is the HTML tag that contains the entire table, so I tell Selenium to find this element.
I use the nifty highlightElement function to confirm graphically in the browser that this is what I think it is.
Then it’s business as usual.
I parse the string output from Selenium into an HTML tree and use XPath to parse the table for just the fund name and ticker.
>library('XML')
master <- >c()
n <- 5 ># number of pages to scrape.
80 pages in total.
I just scraped 5 pages for this example.
>for(i >in 1:n) {
site <- >paste0("https://www.fidelity.com/fund-screener/evaluator.shtml#!&ntf=N&ft=BAL_all&msrV=advanced&sortBy=FUND_MST_MSTAR_CTGY_NM&pgNo=",i) ># create URL for each page to scrape
remDr$navigate(site) ># navigates to webpage
elem <- remDr$findElement(using="id", value="tbody") ># get big table in text string
elem$highlightElement() ># just for interactive use in browser.
not necessary.
elemtxt <- elem$getElementAttribute("outerHTML")[[1]] ># gets us the HTML
elemxml <- htmlTreeParse(elemtxt, useInternalNodes=>T) ># parse string into HTML tree to allow for querying with XPath
fundList <- >unlist(xpathApply(elemxml, '//input[@title]', xmlGetAttr, 'title')) ># parses out just the fund name and ticker using XPath
master <- >c(master, fundList) ># append fund lists from each page together
}
>head(master)
## [1] "FidelityAA Global Balanced Fund (FGBLX)"
## [2] "FidelityAA Global Strategies Fund (FDYSX)"
## [3] "Fidelity FreedomA 2055 Fund (FDEEX)"
## [4] "Aberdeen Dynamic Allocation Fund Class A (GMMAX)"
## [5] "Aberdeen Dynamic Allocation Fund Class C (GMMCX)"
## [6] "AllianceBernstein Real Asset Strategy Advisor Class (AMTYX)"
Step 3: Extract ticker
Nothing fancy here – just separating the ticker from the fund name.
master2 <- >data.frame(>sapply(master, >function(x) >substr(x, >nchar(x)-5, >nchar(x)-1)))
master2$name <- >sapply(master, >function(x) >substr(x, 0, >nchar(x)-8))
>names(master2) <- >c('ticker', 'name')
>head(master2)
## ticker name
## 1 FGBLX FidelityAA Global Balanced Fund
## 2 FDYSX FidelityAA Global Strategies Fund
## 3 FDEEX Fidelity FreedomAA 2055 Fund
## 4 GMMAX Aberdeen Dynamic Allocation Fund Class A
## 5 GMMCX Aberdeen Dynamic Allocation Fund Class C
## 6 AMTYX AllianceBernstein Real Asset Strategy Advisor Class
What else can Selenium do?
My little example makes use of the simple functionality provided by Selenium for web scraping – rendering HTML that is dynamically generated with Javascript or Ajax.
Since Selenium is actually a web automation tool, one can be much more sophisticated by using it to automate a human navigating a webpage with mouse clicks and writing and submitting forms.
This can be a huge time saver for researchers that rely on front-end interfaces on the web to extract data in chunks.
Here’s a basic example using Python.
Here’s a basic example using R.
Getting setup
On the several computers I use, I’ve found setup ranging from seamless to frustrating.
The most frustrating issue I encountered while setting up on my Mac was this error message:
> remDr$>open()
[1] "Connecting to remote server"
Error: Summary: UnknownError
Detail: An unknown server-side error occurred >while processing the command.
>class: java.lang.IllegalStateException
I was able to resolve it by killing all processes running on port 4444 and trying again.
At the terminal:
lsof -i :4444
Kill PIDs of any processes listed.
For example:
kill 30681
Python 進階爬蟲技巧 selenium + chrome
隨著網路教學資源的豐富,簡易的爬蟲稍微有點程式基礎就可以寫出來,這間接導致很多網站加上了 captcha 來避免爬蟲,由於 captcha 是由 javascript 產生,這幾乎就阻擋了大部分的簡易爬蟲 (如 requests + bs4)。
之前一直有再用 requests + bs4 來做自動簽到,但最近這網站突然加上了 captcha,導致爬圖突然不能用了,買一個進階會員需要 500 RMB,想了一下還是決定土炮弄一套進階的簽到程式,並跑在 linode (cloud server) 上,用以達到每天簽到的功能。
這邊文章會教你如何使用 selenium + chrome 模擬瀏覽器行為抓取資料,並分享我踩到的各種雷,有興趣歡迎 follow。
原始碼在 https://github.com/kcfang/python-selenium-crawler
系統設置
這邊使用 docker ubuntu 18.04 image 作範例。
安裝 Python3 + Selenium
apt update
apt install -y python3 python3-pip
pip install selenium
安裝 Chrome + Chromedriver (selenium調用接口)
安裝 chrome
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
apt install ./google-chrome-stable_current_amd64.deb
查看 chrome 版本
google-chrome --version
Google Chrome 74.0.3729.131
到chrome driver網站下載對應版本的 driver。
安裝 chrome driver (v74版)
wget https://chromedriver.storage.googleapis.com/74.0.3729.6/chromedriver_linux64.zip
這邊將 chromedriver 放到家目錄下 (docker image以/root為家目錄)
unzip chromedriver_linux64.zip -d /root/
Selenium 簡易教學 + 安裝測試
Selenium 的主要功能是透過程式去操作網頁 DOM,所以很多公司都拿 Selenium 來寫前端的自動化測試,我們要做的就是使用 Selenium 模擬人工的行為。
#!/usr/bin/python3
# python yahoo.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
if __name__ == "__main__":
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
driver = webdriver.Chrome('~/chromedriver', chrome_options=options)
driver.set_window_size(1024, 960)
# 使用 driver 開起 https://tw.yahoo.com
driver.get("https://tw.yahoo.com")
# 使用 xpath 找到搜尋欄並填入 hello world
inputs = driver.find_element_by_xpath('//*[@id="UHSearchBox"]')
inputs.send_keys("hello world")
# 找到送出鍵並點擊
driver.find_element_by_xpath('//*[@id="UHSearchWeb"]').click()
# 將目前頁面存到 yahoo.png
driver.save_screenshot('yahoo.png')
上面的程式簡單透過 chromedrive 控制 chrome,由於我程式是跑在 cloud server 上,所以需要加上 --headless 及 --no-sandbox 選項,這樣 chromedriver 就不需要開啟 chrome。
直接執行 yahoo.py 可以看到當前資料夾出現了一張 yahoo.png。
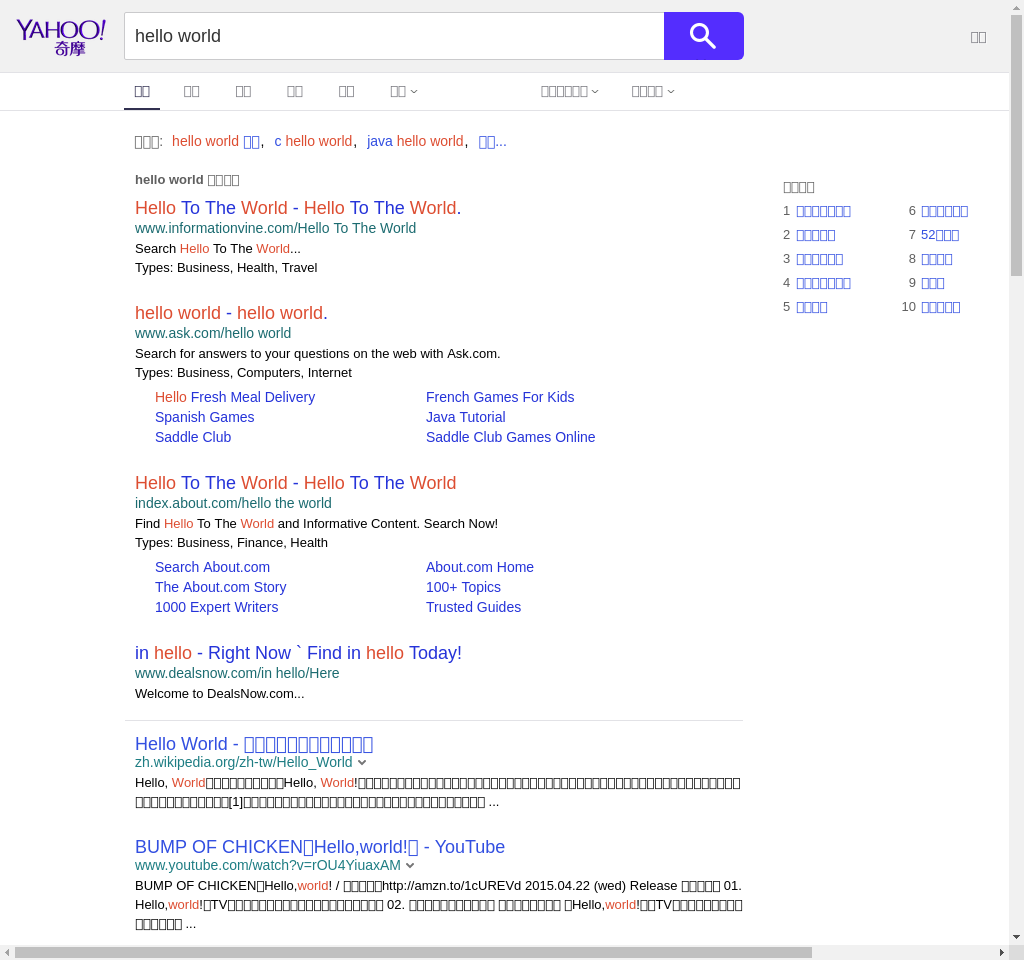 比較值得注意的是粗體的那行 driver.set_window_size(1024, 960),由於 Selenium 是模擬瀏覽器行為,瀏覽器大小也會直接影響結果,我在抓取 captcha 的時候就踩到瀏覽器視窗不夠大的坑,這讓我 debug 了半小時…
比較值得注意的是粗體的那行 driver.set_window_size(1024, 960),由於 Selenium 是模擬瀏覽器行為,瀏覽器大小也會直接影響結果,我在抓取 captcha 的時候就踩到瀏覽器視窗不夠大的坑,這讓我 debug 了半小時…
疑難排解
問題 1.
selenium.common.exceptions.WebDriverException: Message: unknown error: session deleted because of page crash from tab crashed
如果遇到 Message: unknown error: session deleted because of page crash
from tab crashed,有可能的原因是你的系統資源不夠,由於我是跑在最便宜的 cloud server 上,1G 的 RAM 可能會支撐不住 Chrome 的摧殘…
如果遇到就把程式用不到的程式關一關,chrome / chromedriver 也都砍到掉,然後再重跑一次。
問題 2.
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
這是因為 chromedriver 找不到,請確認 chromedriver 有放到 ${HOME} 下。
問題 3.
selenium.common.exceptions.WebDriverException: Message: unknown error: Chrome failed to start: crashed
這有兩個可能
chromedriver / chrome 版本對不上,請參考教學重新下載正確的 chromedriver。
與問題 1 一樣,資源不夠連開都開不起來 orz…
如何找到 DOM 的 xpath
打開開發人員工具,選取需要的 DOM,右鍵→Copy→Copy XPath。
![]()
小結
基本上到這邊就可以簡單使用 selenium + chrome 對網頁進行操作,
highlightElement function to confirm graphically in the browser that this is what I think it is.
Then it’s business as usual.
I parse the string output from Selenium into an HTML tree and use XPath to parse the table for just the fund name and ticker.
>library('XML')
master <- >c()
n <- 5 ># number of pages to scrape.
80 pages in total.
I just scraped 5 pages for this example.
>for(i >in 1:n) {
site <- >paste0("https://www.fidelity.com/fund-screener/evaluator.shtml#!&ntf=N&ft=BAL_all&msrV=advanced&sortBy=FUND_MST_MSTAR_CTGY_NM&pgNo=",i) ># create URL for each page to scrape
remDr$navigate(site) ># navigates to webpage
elem <- remDr$findElement(using="id", value="tbody") ># get big table in text string
elem$highlightElement() ># just for interactive use in browser.
not necessary.
elemtxt <- elem$getElementAttribute("outerHTML")[[1]] ># gets us the HTML
elemxml <- htmlTreeParse(elemtxt, useInternalNodes=>T) ># parse string into HTML tree to allow for querying with XPath
fundList <- >unlist(xpathApply(elemxml, '//input[@title]', xmlGetAttr, 'title')) ># parses out just the fund name and ticker using XPath
master <- >c(master, fundList) ># append fund lists from each page together
}
>head(master)
## [1] "FidelityAA Global Balanced Fund (FGBLX)"
## [2] "FidelityAA Global Strategies Fund (FDYSX)"
## [3] "Fidelity FreedomA 2055 Fund (FDEEX)"
## [4] "Aberdeen Dynamic Allocation Fund Class A (GMMAX)"
## [5] "Aberdeen Dynamic Allocation Fund Class C (GMMCX)"
## [6] "AllianceBernstein Real Asset Strategy Advisor Class (AMTYX)"
Step 3: Extract ticker
Nothing fancy here – just separating the ticker from the fund name.
master2 <- >data.frame(>sapply(master, >function(x) >substr(x, >nchar(x)-5, >nchar(x)-1)))
master2$name <- >sapply(master, >function(x) >substr(x, 0, >nchar(x)-8))
>names(master2) <- >c('ticker', 'name')
>head(master2)
## ticker name
## 1 FGBLX FidelityAA Global Balanced Fund
## 2 FDYSX FidelityAA Global Strategies Fund
## 3 FDEEX Fidelity FreedomAA 2055 Fund
## 4 GMMAX Aberdeen Dynamic Allocation Fund Class A
## 5 GMMCX Aberdeen Dynamic Allocation Fund Class C
## 6 AMTYX AllianceBernstein Real Asset Strategy Advisor Class
What else can Selenium do?
My little example makes use of the simple functionality provided by Selenium for web scraping – rendering HTML that is dynamically generated with Javascript or Ajax. Since Selenium is actually a web automation tool, one can be much more sophisticated by using it to automate a human navigating a webpage with mouse clicks and writing and submitting forms. This can be a huge time saver for researchers that rely on front-end interfaces on the web to extract data in chunks. Here’s a basic example using Python. Here’s a basic example using R.Getting setup
On the several computers I use, I’ve found setup ranging from seamless to frustrating. The most frustrating issue I encountered while setting up on my Mac was this error message:> remDr$>open()
[1] "Connecting to remote server"
Error: Summary: UnknownError
Detail: An unknown server-side error occurred >while processing the command.
>class: java.lang.IllegalStateException
I was able to resolve it by killing all processes running on port 4444 and trying again.
At the terminal:
lsof -i :4444
Kill PIDs of any processes listed.
For example:
kill 30681
Python 進階爬蟲技巧 selenium + chrome
隨著網路教學資源的豐富,簡易的爬蟲稍微有點程式基礎就可以寫出來,這間接導致很多網站加上了 captcha 來避免爬蟲,由於 captcha 是由 javascript 產生,這幾乎就阻擋了大部分的簡易爬蟲 (如 requests + bs4)。 之前一直有再用 requests + bs4 來做自動簽到,但最近這網站突然加上了 captcha,導致爬圖突然不能用了,買一個進階會員需要 500 RMB,想了一下還是決定土炮弄一套進階的簽到程式,並跑在 linode (cloud server) 上,用以達到每天簽到的功能。 這邊文章會教你如何使用 selenium + chrome 模擬瀏覽器行為抓取資料,並分享我踩到的各種雷,有興趣歡迎 follow。 原始碼在 https://github.com/kcfang/python-selenium-crawler系統設置
這邊使用 docker ubuntu 18.04 image 作範例。安裝 Python3 + Selenium
apt update apt install -y python3 python3-pip pip install selenium安裝 Chrome + Chromedriver (selenium調用接口)
安裝 chrome wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb apt install ./google-chrome-stable_current_amd64.deb 查看 chrome 版本 google-chrome --version Google Chrome 74.0.3729.131 到chrome driver網站下載對應版本的 driver。 安裝 chrome driver (v74版) wget https://chromedriver.storage.googleapis.com/74.0.3729.6/chromedriver_linux64.zip 這邊將 chromedriver 放到家目錄下 (docker image以/root為家目錄) unzip chromedriver_linux64.zip -d /root/Selenium 簡易教學 + 安裝測試
Selenium 的主要功能是透過程式去操作網頁 DOM,所以很多公司都拿 Selenium 來寫前端的自動化測試,我們要做的就是使用 Selenium 模擬人工的行為。 #!/usr/bin/python3 # python yahoo.py from selenium import webdriver from selenium.webdriver.chrome.options import Options if __name__ == "__main__": options = Options() options.add_argument('--headless') options.add_argument('--no-sandbox') driver = webdriver.Chrome('~/chromedriver', chrome_options=options) driver.set_window_size(1024, 960) # 使用 driver 開起 https://tw.yahoo.com driver.get("https://tw.yahoo.com") # 使用 xpath 找到搜尋欄並填入 hello world inputs = driver.find_element_by_xpath('//*[@id="UHSearchBox"]') inputs.send_keys("hello world") # 找到送出鍵並點擊 driver.find_element_by_xpath('//*[@id="UHSearchWeb"]').click() # 將目前頁面存到 yahoo.png driver.save_screenshot('yahoo.png') 上面的程式簡單透過 chromedrive 控制 chrome,由於我程式是跑在 cloud server 上,所以需要加上 --headless 及 --no-sandbox 選項,這樣 chromedriver 就不需要開啟 chrome。 直接執行 yahoo.py 可以看到當前資料夾出現了一張 yahoo.png。
比較值得注意的是粗體的那行 driver.set_window_size(1024, 960),由於 Selenium 是模擬瀏覽器行為,瀏覽器大小也會直接影響結果,我在抓取 captcha 的時候就踩到瀏覽器視窗不夠大的坑,這讓我 debug 了半小時…